Been a while since my last post. Over the last couple of months I’ve been tinkering with using Code Stream to deploy a Nested Esxi / vCenter environment.
My starting point is William Lams excellent PowerShell script (vsphere-with-tanzu-nsxt-automated-lab-deployment). I also wanted to use the official vmware/poweclicore docker image.
Well let’s just say it’s been an adventure. Much has been learned through trial and (mostly) error.
For example in Williams script, all of the files are located on the workstation where the script runs. Creating a custom docker image with those files would have resulted in a HUGE file, almost 16GB (Nested ESXi appliance, vCSA appliance and supporting files, and NSX-T OVA files). As one of my co-worker says, “Don’t be that guy”.
At first I tried cloning the files into the container as part of the CI setup. Downloading the ESXi OVA worked fine, but failed when I tried copying over the vCSA files. I think it’s just too much.
I finally opted to use a Kubernetes Code Stream instead of a Docker pipeline. This allowed me to use a Persistent Volume Claim.
Kubernetes setup
Some of the steps may lack details, as this has been an ongoing effort and just can’t remember everything. Sorry peeps!
Create two Name Spaces, codestream-proxy and codestream-workspace. Codestream-proxy is used by Code Stream to host a Proxy pod.

Codestream-workspace will host the containers running the pipeline code.
Next came the service account for Code Stream. The path of least resistance was to simply assign ‘cluster-admin’ to the new service account. NOTE: Don’t do this in a production environment.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: cs-cluster-role-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: codestream
apiGroup: ""
namespace: defaultNext came the Persistent Volume (pv) and Persistent Volume Claim (pvc). My original pv was set to 20GI, which after some testing was determined too small. It was subsequently increased it to 30GI. The larger pv allowed me to retain logs and configurations between runs (for troubleshooting).
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
name: cs-persistent-volume-cw
spec:
accessModes:
- ReadWriteMany
capacity:
storage: 30Gi
hostPath:
path: /mnt/nested
persistentVolumeReclaimPolicy: RetainapiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cs-pvc-cw
namespace: codestream-workspace
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 30Gi
volumeName: cs-persistent-volume-cwThe final step in k8s is to get the Service Account token. In this example the SA is called ‘codestream’ (So creative).
k get secret codestream-token-blah!!! -o jsonpath={.data.token} | base64 -d | tr -d "\n"
eyJhbGciOiJSUzI1NiIsImtpZCI6IncxM0hIYTZndS1xcEdFVWR2X1Z4UFNLREdQcGdUWDJOWUF1NDE5YkZzb.........Copy the token, then head off to Code Stream.
Codestream setup
There I added a Variable to hold the token, called DAG-K8S-Secret.
Then went over to Endpoints, where I added a new Kubernetes endpoint.

Repo setup
The original plan was to download the OVA/OVF files from a repo every time the pipeline ran. However an error would occur on every VCSA file set download. Adding more memory to the container didn’t fix the problem, so I had to go in another direction.
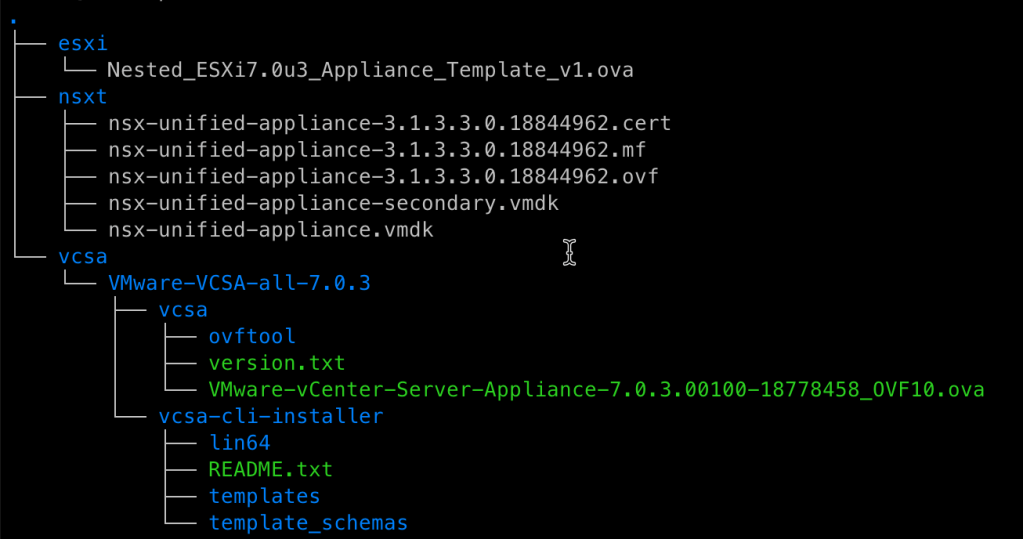
The repo is well connected to the k8s cluster, so the transfer is pretty quick. Here is the directory structure for the repo (http://repo.corp.local/repo/).
NOTE: You will need a valid account to download VCSA and NSX-T.
NOTE: NSX-T will be added to the pipeline later.
Simply copying the files interactively on the k8s node seemed like the next logical step. Yes the files copied over nicely, but any attempt to deploy the VCSA appliance would throw a python error complaining about a missing ‘vmware’ module.
However I was able to run the container manually, copy the files over and run the scripts successfully. Maybe a file permissions issue?
Finally I ran the pipeline with a long sleep at the beginning. Using an interactive session, and copied the files over. This fixed the problem.
Here are the commands I used to copy the files over interactively.
k -n codestream-workspace exec -it po/running-cs-pod-id bash
wget -mxnp -q -nH http://repo.corp.local/repo/ -P /var/workspace_cache/ -R "index.html*"
# /var/workspace_cache is the mount point for the persistent volume
# need to chmod +x a few files to get the vCSA to deploy
chmod +x /var/workspace_cache/repo/vcsa/VMware-VCSA-all-7.0.3/vcsa/ovftool/lin64/ovftool*
chmod +x /var/workspace_cache/repo/vcsa/VMware-VCSA-all-7.0.3/vcsa/vcsa-cli-installer/lin64/vcsa-deploy*This should do it for now. The next article will cover some of the pipeline details, and some of the changes I had to make to William Lams Powershell code.
Happy holidays.
