My current customer asked if they could use the same vSphere template as an AWS AMI. The current vSphere template has a custom disk layout to help them troubleshoot issues. The default single disk layout for AMI’s actually hinders their troubleshooting methodology.
Aside from the custom disk layout, I know VMtools would have to be replaced with cloud-init. Sure no problem. RIGHT! Well actually it wasn’t that hard.
Well I was finally able get it to work, and learned a bunch along the way. Those lessons include,
- The RHEL default DHCP client is incompatible with AWS.
- EFI bios is only supported in larger, more expensive instances.
- AWS VM image import.
- Make sure to enable ‘disable_vmware_customization’, if that made sense.
Requirements
- AWS roles, policies and permissions per this document.
- S3 bucket (packer-import-example) to store the VMDK until it is imported.
- Basic IAM user (packer) with the correct permissions assigned (see above).
- vSphere environment to build the image.
- A RHEL 8.x DVD ISO for installation.
- HTTP repo to store the kickstart file.
Now down to brass tacks. To be honest it took lots of trial and error (mostly error) to get this working right. For example, on one pass Cloud-Init wouldn’t run on the imported AMI. After looking at cloud.cfg I noticed ‘disable_vmware_customization’ was set to false instead of ‘true’. Another error occurred when my first import attempt failed as the machine did not have a ‘DHCP client’. That was odd as it booted up fine in vSphere and got an IP Address. Apparently AWS only supports certain DHCP clients. Go figure.
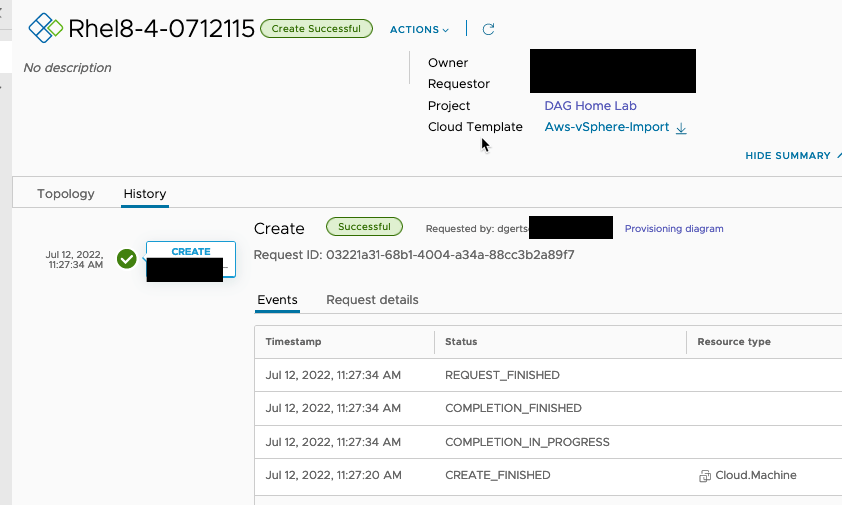
Eventually the machine booted properly in AWS, with the user-data applied correctly. The working user-data is in the repo’s cloud-init directory.
And my super simple vRAC blue print even worked. This simple BP adds a new user, assigns a password, and grants it SUDO permissions.
A couple of notes on the packer amazon-import post processor. Those include,
- The images are encrypted by default, even tho the default for ‘ami_encrypt’ is false by default.
- ‘ami_name’ requires the AWS permission of ec2:CopyImage on the policy for the import role.
- Don’t use the default encryption key if you wish to share this. You’ll need a Customer Managed Key (CMK). The import role (vmimport) will need to be a key user. You can set this with ‘ami_kms_key’ set to the Id of the CMK (i.e., ebea!!!!!!!!-aaaa-zzzz-xxxxxxxxxxxxxx)
- The CMK needs to be shared with the target customer before sharing the AMI. ‘ami_org_arns’ allows you to set the organizations you’d like to share the AMI with.
- There are lots of import options, you can check them out here.
This working example, plus others I’ve been working are available in this github repo.
Now onto another vRAC adventure.