Now that I’ve spent a couple of months with vRealize Automation Cloud (vRAC) (AKA VMware Cloud Assembly) I figured it would be a good time to jot down some lessons learned from deploying and using several Ansible Control Hosts (ACH).
My first ACH was an Ubuntu machine deployed on our vSphere cluster. This deployment model requires connectivity to a Cloud Proxy. All of my ACH’s since then have been on an AWS t2.micro Amazon Linux instance. The remaining blog focuses on that environment.
First you should assign an Elastic IP if you plan on shutting it down when not in use. Failing to do so makes your vRAC integrated control host unreachable when it reboots, as the IP will change.
This leaves you with an unusable ACH, with no option but to replace it with a new one. A word of warning here, make sure to delete any deployments that used that ACH. Failing to do so will leave you with an undeletable deployment. Plus you may not even be able to delete the ACH from the integrations page. Oh joy!
Next is the AWS security group. The off shore developers cannot provide a list of source IP’s for any vRAC call into the ACH. Or in other words you have to open your server up to the world. I’ve been told they are working on this, but do not know when they’ll have a fix.
So, I’ve been experimenting with ConfigServer Security and Firewall (CSF). My current test is pretty out of the box and is using two block lists in csf.blocklists. So far so good, as I was able to add the test ACH without an issue, and it is blocking tons of IP’s. The host is using about 180K of RAM with the blocklists in place.
Changing the SSH server port to something other than port 22 doesn’t work right now. I brought this up on my weekly VMware call, so hopefully they’ll get it fixed in the near future.
I’m using an S3 bucket to backup my playbooks once a day. I did have to create an IAM Role with S3 permissions and assigned it to my ACH. I’ll eventually the files pushed up to a repository.
Now on to troubleshooting. One of my beefs is the naming convention of the log files in the ACH users home directory (var/tmp/vmware/provider/user_defined_script/). The only way to figure out which directory to look in is to list them by date (ls -alt) or do a find on the machine IP.
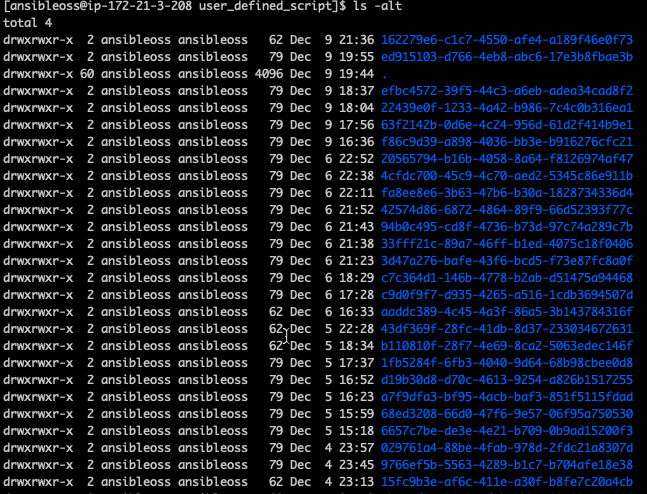
The ACH playbook log directory contains different files depending on the run state. A running deployment contains additional information like what the actual ansible command was called (exec). Exec disappears when the deployment is complete or it errors out, making it almost impossible to look at the ansible command and figure out why it failed. My work around is to quickly jump into the directory and print out ‘exec’.
The ansible command isn’t the only thing that is deleted when a deployment fails, they also delete the host and user variables under /etc/ansible/host_vars/{ip address}. I just keep two windows open, and print out the contents of anything beginning with ‘vra*’. However, ‘log.txt’ in the deployment log folder does contain the extra host variables, but does not contain the user variables.
I’m still figuring out how much space I need in the users home directory for log files. vRAC doesn’t delete folders when destroying a deployment. I suspect an active ACH will eventually fill up the ACH user log files (var/tmp/vmware/provider/user_defined_script/). Right now I’m seeing an average folder size of a bit less than 20k for completed deployments, or about 1G per 60 deployments. And no this isn’t on my grip list yet, but will be.
That’s it for now. Come back soon.
